
Over the years, there were many competing approaches to data storage and querying. The oldest and best-known database is a relational database, where the data is organized into relations called a table. To overcome the drawbacks of Relational Database like scalability, a document model database is introduced the term NoSql got famous. The term NoSQL represents all databases that are not Relational Databases. NoSQL itself has many types of databases that is what we are going to see now.
1. Relational Database
This is the oldest form of data storage, here the smallest persona in data is considered as a table. For example, we have to represent data of students, teachers, and the course. Here we will have 3 tables for students, teachers, and the course.
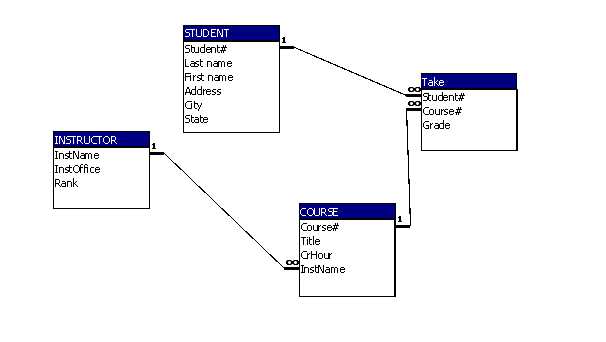
Where each row inside a table considers as an individual entity. Each row inside a student table will represent a student and his/her details.
Example – MySql, Postgres
Pros:
- Works for almost every scenario
- ACID-compliant
- Allow us to fire complex queries
Cons:
- Scalability
- We should know the schema beforehand, not suitable for unstructured data.
2. Key-Value Pair

This is one type of NoSql, here the data is stored in the format of key-value pair. It’s like HashMap of java or Dictionary in C#, python. The most common use case is, these databases are used as caching layers as data is stored in memory in form of key-value pair.
Example: Redis, Memcached
Pros:
- Fast access
- Best for caching
Cons:
- Limited Space
- No complex queries can be performed
- Not persistent, because data are stored in memory
3. Wide Column Database

A wide column database is an extension of the Key-Value pair database, where the data is stored in the form of a key and a group of columns. Key -> { column1, column2 }. Mostly used for time series data like logging or where writes to the database is high
Example: Cassandra, Apache Hbase
Pros:
- Schemaless
- Scalable and Replication can be done easily.
Cons:
- Not suitable high read scenarios
- No Joins
4. Document Model Database

Here the data is stored in the form of documents, each document will have information in the format of key-value pair, it is schema-less, well some library allows us to enforce schema to the DB but in it true self it is schema-less.
Example: MongoDB, CouchDB
Pros:
- Suitable for unstructured data
- Schemaless
- Easy to scale
- Suitable for hierarchical data storage
Cons:
- No ACID-compliant
- Joins are headaches here!
5. Graph Data Model
Here the data are represented as nodes and the relation between them as edges
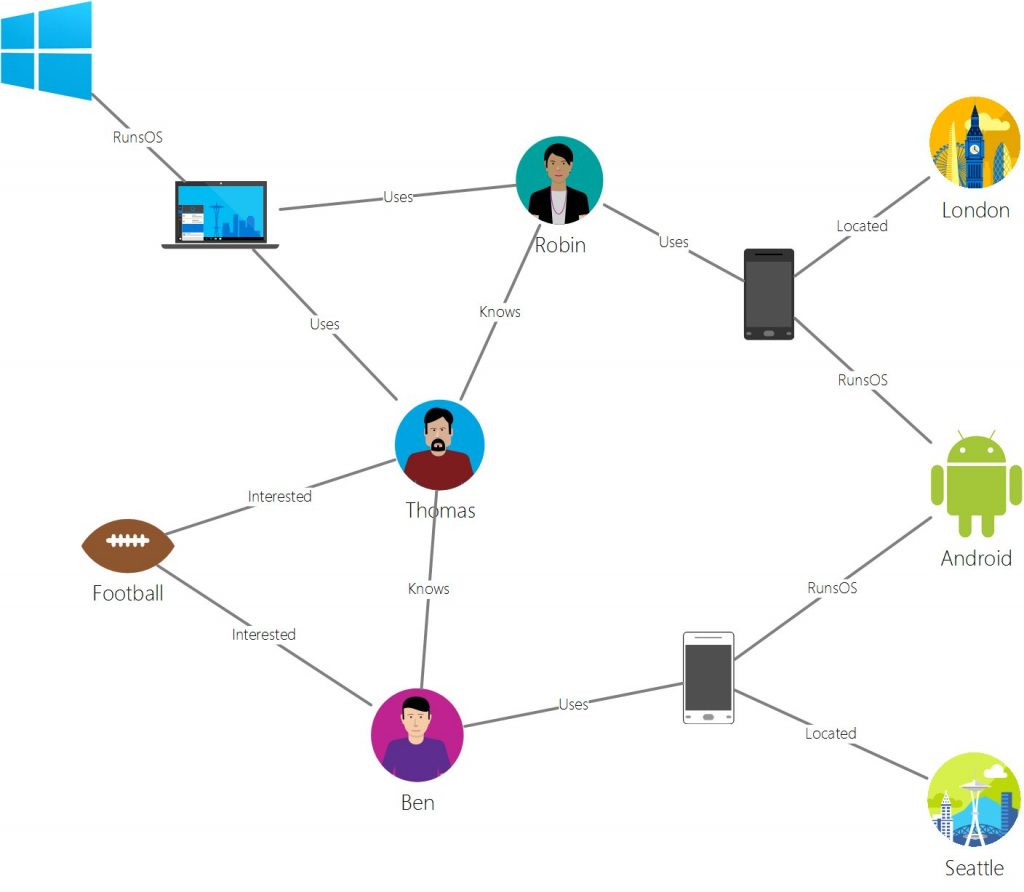
Example: Neo4j
Pros:
- Suitable for Knowledge graph
- Recommendation Engine
Cons:
- Hard to visualize complex data.
6. Search Databases

Here the data is stored in the form of documents but along with that, the database has an inverted index for fast search. An Inverted index is like an Index behind a book. For a given word we can find all the documents which has this word.

Example: Elastic Search
Pros:
- Used for fast search
- Suitable for searching and typehead.
- Fuzzy Search is possible
- Scalable
Cons:
- Solves problem for small use case, cannot be used as primary database like mongo DB
7. Multi-Model Database
Here we use multiple databases to achieve our use case with the help of APIs. An example of such a database is GraphQL. https://graphql.org/