It’s important to understand how database stores data internally, understanding this allows us to understand why a query runs fast or slow. Before diving in, let’s clear out some computer fundamentals, all the data on a computer is stored as streams of 1s and 0s as blocks/pages on the drive, Databases use these blocks and arrange them efficiently to query the data. Let’s understand some building blocks of storage internals
Row Id
Databases consist of tables and each table has many rows, every row in the table has a unique Id, which is generated by the Database or can be User-defined which is the primary key.
In short, a unique identifier of a row in a table is called Row Id.
Page
The rows are a logical view of the database, pages are how the rows are stored in the database, pages are fixed-size blocks example 8kb, etc. a single page will have multiple rows of a table, how many rows? That depends on each row size. A database cannot fetch a single row from the hard drive, it always read a page or many pages in a single IO operation.
IO(Input/Output) Operation
The process of reading a page from an OS hard drive or OS cache is an IO operation for the database. IO operations are slow, so if a query takes a lot of time to execute one of the possible reasons is database is performing heavy IO operations.
Heap:
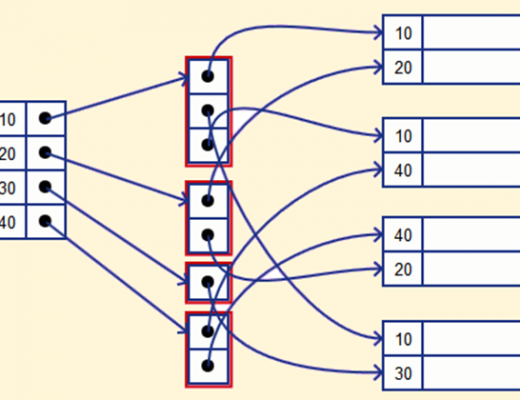
Heap is a logical presentation of the entire table in the memory, it consists of all the pages of a table that are linked with each other using pointers, they are not stored in sorted order. Don’t think this as Heap.
There is another version where the pages are arranged in sorted order, this is also called a clustered index. Primary declared in MySql is used to create a clustered index. In Postgres, there is no clustered index, all the index point to row id which presents in heap.
Index
Traversing a heap is expensive, we have to traverse each page in the worst case to find a row. To optimize these, indexes are used. The index is another data structure that is in sorted format and has pointers to the heap pages. This helps us to skip unwanted traversal of pages in the heap. An index is applied on column/s they are sorted as per column/s given. The index doesn’t store all the info of the row while the heap does so it is small in size comparative to the heap.
Example:
Consider you have a table of employees with 1000 entires
if we query
select * from employees where id = 1000
If we don’t have an index: The database goes to heap and starts searching row with employee id 1000, in worst case if the heap has 500 pages, the database will read all the 500 pages.
If we have an index on the id column: As we already have a data structure that is in sorted as per employee id, we can easily traverse using B-tree and get the pointer. Assume we get the pointer as 499 we can directly go to page 499 instead of traversing 1 by 1.